Team Babylon! 💣 CS 175: Project in AI (in Minecraft)
PROJECT SUMMARY: The goal of our project is to create and compare two Malmo agents that learn to fight enemies using Q-learning. One will learn to use a general fighting strategy that is independent of the type of enemy that it is fighting. The other will be a specialist, in that it takes into account the type of enemy it is fighting and makes more informed decisions using this information. By using Q-Learning, we are training our agent to make decisions based on the current state of its fight with a mob. Our hope is that the specialist agent, with its more informed world-state, will eventually learn to tailor its combat strategy to specific enemy types, and therefore become more effective than the generalist.
APPROACH:
Update Equation:
r is the reward for the current action.
G = gamma * r
oldq = q_table[state][action]
q_table[state][action] = oldq + alpha * (G - oldq)
Our bot currently begins in an arena with a single enemy. As its q-table is initially empty, it begins selecting actions at random, but remains facing the enemy at all times. From any given state, the same possible actions are available which include move forward or backward, stop, strafe left or right, and attack. While the aim of the bot is updated every 10ms for accuracy, a new action is chosen every 200ms, clearing the old action to ensure that decisions from previous world states do not interfere with the current one.
States of MDP: In order to use Q-learning, our program separates the world into several different states. Our main two observations used in determining the current world state are our distance from the enemy and our current health. As distance is a continuous variable, and therefore results in an unreasonably large number of world states to make learning practical, we separate the distances into three discrete categories. In a similar manner, having many different possible levels of health is not productive when trying to learn, as it makes the agent unlikely to land in the same world state twice with a very large state space. Therefore, we discretize health into three categories as well. This reduces our state space significantly and therefore allows the agent to learn more quickly. Our categories are as follows:
Distance: { d <= 3: ‘Melee’, 3 < d <= 10: ‘Near’, d > 10: ‘Far’ }
Health: { h <= 2: ‘Low’, 2 < h <= 12: ‘Med’, h > 12: ‘Hi’ }
Given that we are using the specialist bot, we add an extra state to the world: enemy type. The purpose of this extra state is to allow the bot to make more informed decisions about whether to attack, or move forward or backward based on the enemy that it is fighting. Ideally, this bot should eventually noticeably outperform the generalist bot, by applying a strategy specific to the type of enemy it is fighting.
Reward Function: Our current reward function remains simple as we are still experimenting with metrics that may improve its effectiveness at teaching our agent combat. In its current iteration, the agent learns on two metrics, our change in health since the last action, and the damage dealt since the last action. These are meant to encourage the bot to find a balance between maintaining health and dealing damage to the enemy. While the agent health is easily obtained by getting the world state and searching through the observations, the damage dealt is not available within the world observations. In order to access enemy health, one of our team members became a contributor to the Malmo repository and made modifications to generate the enemy health observations, and therefore enabled our team and other Malmo users to access the enemy’s health.
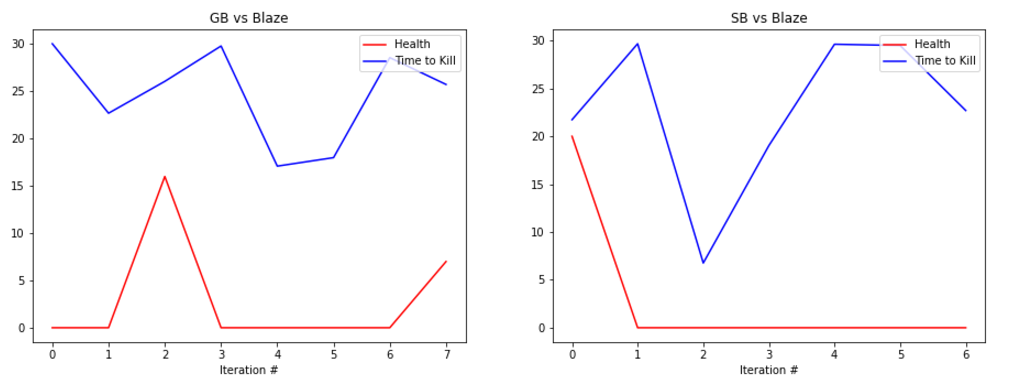
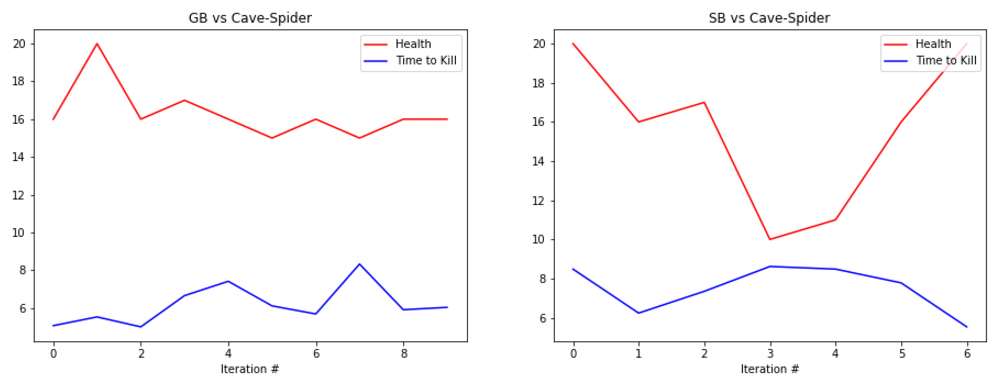
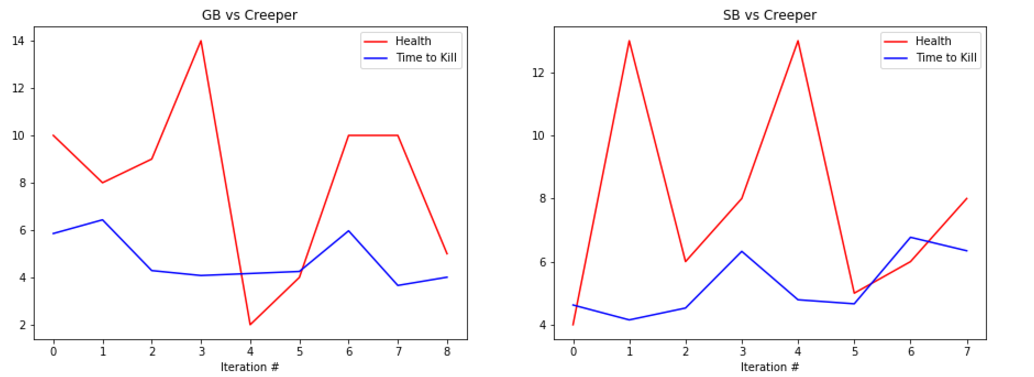
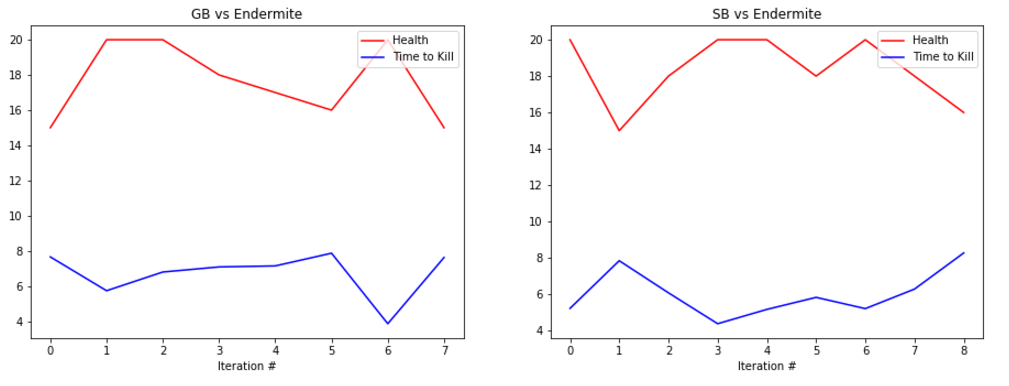
EVALUATION: To evaluate our prototype’s performance we are collecting statistics such as the health of the agent at the end of the round along with the time that it took the agent to kill the enemy, or timeout. Below are some graphs showing its performance.
The graphs show the total amount of health remaining after the fight in red and the time taken to kill the mob in blue (30s if we failed to kill the enemy). The number at the bottom represents the number of iterations we ran the bot. It is important to note that because updates to the q-table happen per action, not per round, the relatively small number of rounds yields a significant number of updates, and therefore a significant amount of learning.
The performance of the generalist bot (‘GB’) and the specialist bot (‘SB’) are displayed side-by-side for comparison.
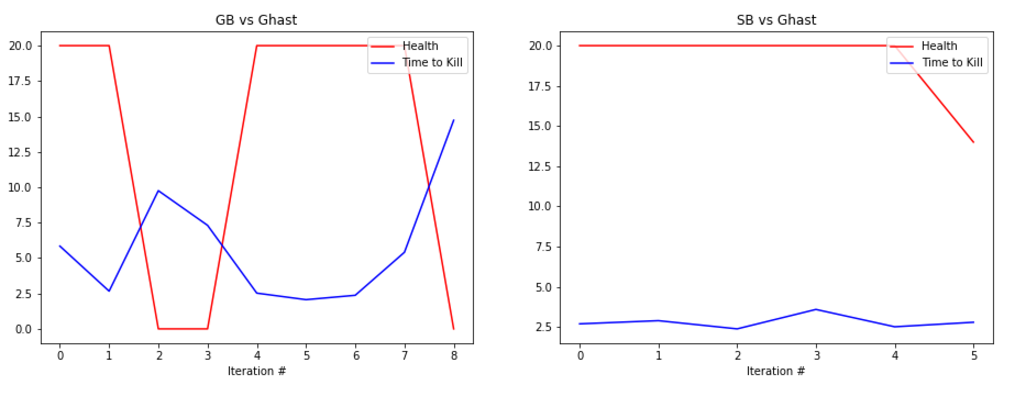
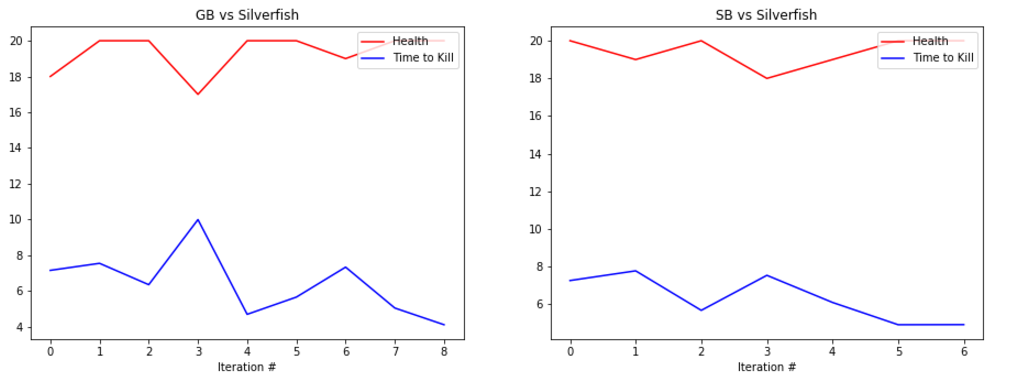
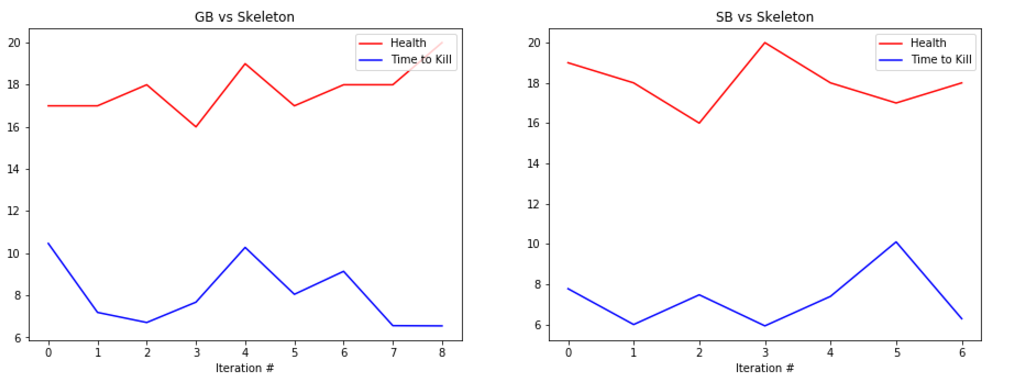
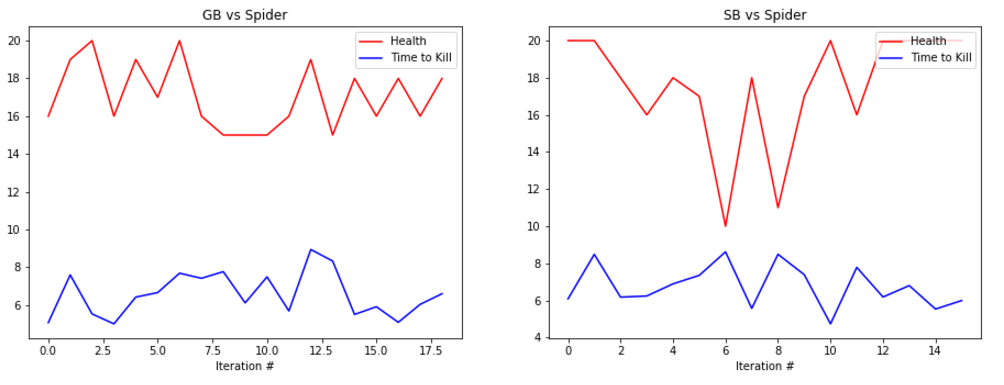
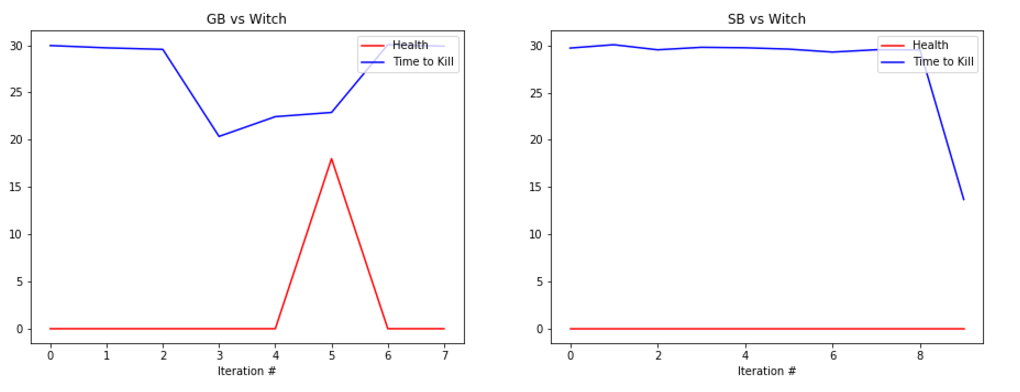
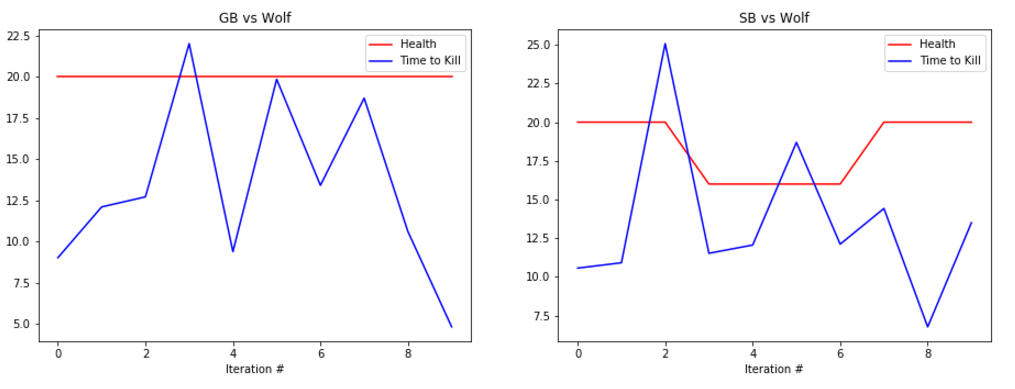
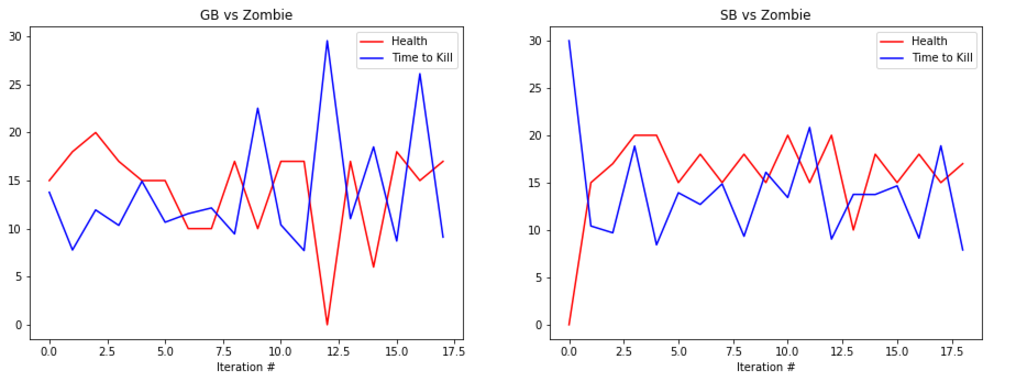
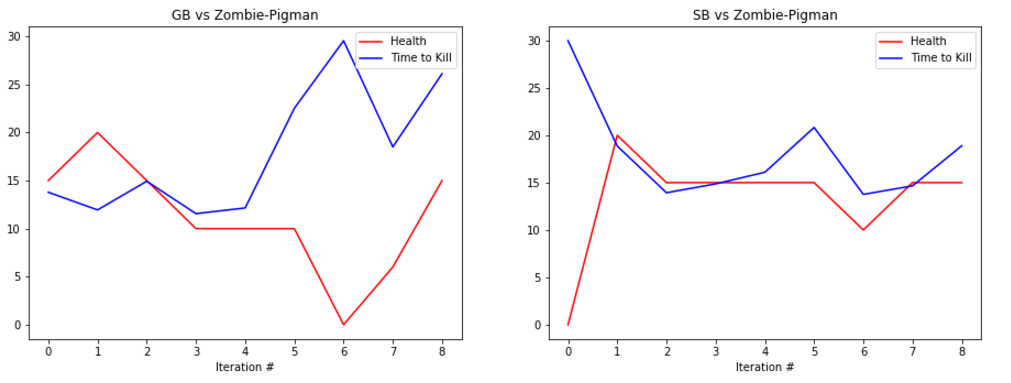
REMAINING GOALS AND CHALLENGES: Our prototype currently lacks the ability to use its bow in combat. Using the bow had proved challenging as the action requires an extended action to draw the bow. Before we consider the project finished we would like to make it possible for our bot to engage at range. In order to accomplish this we believe that we would need to separate movement actions from attack actions, which increases the algorithm complexity but allows the bot to take advantage of the ability to move and attack at the same time.
We also need to perform better evaluation of our model’s optimal policy. Currently, we have not implemented the methods for obtaining and observing this policy, and as such the agent continues to learn as long as the program is running. Our goal moving forward is to implement a way to obtain and run the optimal policy in order to assess its performance using a set policy.
Our prototype is also unaware of the action it previously took. By adding the last action as a part of the state, it allows the prototype to develop attack patterns, like swinging and retreating, at the cost of a large increase in state space.
Finally, one goal that could improve the performance of our bot is to revise our reward calculation. While it is simple, in most cases it accurately rewards the bot’s performance in combat, and actively encourages them to attack the enemies, by giving a large reward for dealing damage, and a large punishment for taking damage. However, there are some problems with this reward calculation. First, we would like to see if there is some way to incorporate time as a factor in order to encourage the bot to kill within the 30 second time limit. Because it is not taken into account in the reward or the state, the bot does not have any motivation to kill the mob faster as the round is coming to a close, it will treat its actions no differently than in the first second of the round. Secondly, for enemies such as creepers, who explode, the damage dealt is calculated as a change in enemy health. While the creeper has been defeated in a sense, it was not actually defeated by the agent, but rather exploded on its own. Under the current method, the agent would be rewarded for this, which does not necessarily reflect a ‘good’ performance in combat.